Tasnim Mohiuddin
I am a Scientist at Qatar Computing Research Institute (QCRI) in the Arabic Language Technologies (ALT) group, where I work on cutting-edge research and development in the field of Large Language Models (LLMs). I am a core contributor to the creation of Fanar, QCRI's flagship LLM focusing on both Arabic and English. I am involved in every critical phase of the LLM lifecycle, including data curation and synthesis, model training, and evaluation. Apart from training LLMs, my current research focuses on domain-specific LLM innovations, including specialized areas such as Code LLMs and Multimodal LLMs.
Before joining QCRI, I was a Researcher at the Huawei Research Center in Singapore, where my work focused on Multimodal Representation Learning. My work at Huawei Research aimed to seamlessly integrate linguistic and visual modalities, enabling the development of robust, cross-domain AI systems.
I hold a Ph.D. in Computer Science and Engineering from Nanyang Technological University (NTU), Singapore, which I completed in June 2022 under the mentorship of Professor Shafiq Joty. My doctoral dissertation was honored with the "Outstanding Ph.D. Thesis Award" which explored innovative approaches to solve low-resource machine translation. During my doctoral studies, I also had the opportunity to work as a research intern at Meta AI Research, mentored by Professor Philipp Koehn on state-of-the-art NLP technologies.
- Dec 2024: FANAR released [1, 2]. Super excited!
- May 2024: Joined QCRI! Excited to work on cutting-edge research in LLMs.
- April 2023: Recieved prestigious Outstanding Ph.D. Thesis Award. Super excited!
- Oct 2022: Paper got accepted at EMNLP 2022!
- June 2022: Joined Huawei Singapore Research Center!
- May 2022: Finished oral defense of my Ph.D journey!
- May 2021: Started summer internship at Facebook AI Research (FAIR) under Philipp Koehn!
- May 2021: Two papers got accepted at ACL 2021!
- Jan 2021: Paper got accepted at EACL 2021!
- Nov 2020: Presented our paper at virtual EMNLP 2020!
- Sept 2020: Our LNMap got accepted at EMNLP 2020!
- July 2020: Presented our journal paper at ACL 2020 virtually!
- Feb 2020: Defended my Qualifying Exam. Became a Ph.D. candidate. Yay!
- Jan 2020: Our journal paper got accepted in Computational Linguistics!
- Aug 2019: Our paper got accepted at EMNLP-IJCNLP 2019!
- June 2019: Travelled to Minneapolis to present our papers at NAACL!
- Feb 2019: Two papers got accepted at NAACL-HLT 2019!
- August 2018: Our journal accepted for publication in Computational Linguistics!
- July 2018: Travelled to Melbourne to present our work at ACL!
- Apr 2018: Our paper on coherence model got accepted at ACL 2018!
- Jan 2018: Started my Ph.D. journey at NTU!
- Dec 2017: Moved to Singapore!
Publications
-
Tasnim Mohiuddin , Philipp Koehn, Vishrav Chaudhary, James Cross, Shruti Bhosale, and Shafiq Joty, "Data Selection Curriculum for Neural Machine Translation". In Findings of 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP 2022), Abu Dhabi, UAE.
[PDF] [Code] -
M Saiful Bari, Tasnim Mohiuddin (Equal Contributions), and Shafiq Joty, "UXLA: : A Robust Unsupervised Data Augmentation Framework for Cross-Lingual NLP". In Proceedings of The Joint Conference of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (ACL-IJCNLP 2021).
[PDF] [Code] -
Tasnim Mohiuddin , M Saiful Bari, and Shafiq Joty, "AugVic: Exploiting BiText Vicinity for Low-Resource NMT". In Findings of The Joint Conference of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (ACL-IJCNLP 2021).
[PDF] [Code] -
Tasnim Mohiuddin , Prathyusha Jwalapuram, Xiang Lin, and Shafiq Joty, "Rethinking Coherence Modeling: Synthetic vs. Downstream Tasks". In Proceedings of the 16th conference of the European Chapter of the Association for Computational Linguistics (EACL 2021), Kyiv, Ukraine.
[PDF] [Resource] -
Tasnim Mohiuddin , M Saiful Bari, and Shafiq Joty, "LNMap: Departures from Isomorphic Assumption in Bilingual Lexicon Induction Through Non-Linear Mapping in Latent Space". In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP 2020).
[PDF] [Presentation] [Code] -
Han-Cheol Moon, Tasnim Mohiuddin (Equal Contributions), Shafiq Joty, and Chi Xu, "A Unified Neural Coherence Model". In Proceedings of the Conference on Empirical Methods in Natural Language Processing and International Joint Conference on Natural Language Processing (EMNLP-IJCNLP 2019), Hong Kong, China.
[PDF] [Presentation] [Code] -
Tasnim Mohiuddin and Shafiq Joty, "Revisiting Adversarial Autoencoder for Unsupervised Word Translation with Cycle Consistency and Improved Training". In Proceedings of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT 2019), Minneapolis, USA.
[PDF] [Presentation] [Poster] [Code] -
Tasnim Mohiuddin , Thanh-Tung Nguyen, and Shafiq Joty, "Adaptation of Hierarchical Structured Models for Speech Act Recognition in Asynchronous Conversation" . In Proceedings of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT 2019), Minneapolis, USA.
[PDF] [Presentation] [Poster] [Code] -
Tasnim Mohiuddin , Shafiq Joty, and Dat Nguyen, "Coherence Modeling of Asynchronous Conversations: A Neural Entity Grid Approach". In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL 2018), Melbourne, Australia.
[PDF] [Poster] [Code]
-
Tasnim Mohiuddin and Shafiq Joty, "Unsupervised Word Translation with Adversarial Autoencoder". Computational Linguistics (Special Issue of Computational Linguistics on Multilingual and Interlingual Semantic Representations for Natural Language Processing) : pages XXX - XXX (2020), MIT press (June 2020).
[PDF] [Presentation] -
Shafiq Joty and Tasnim Mohiuddin, "Modeling Speech Acts in Asynchronous Conversations: A Neural-CRF Approach". Computational Linguistics (Special Issue on Language in Social Media) 44:4 , pages 859 - 894 (2018), MIT press (2018).
[PDF] [Code]
Research
Curriculum Learning for Neural Machine Translation
Neural Machine Translation (NMT) models are typically trained on heterogeneous
data that are concatenated and randomly shuffled. However, not all of the
training data are equally useful to the model. Curriculum training aims to
present the data to the NMT models in a meaningful order.
In this project, we introduce a two-stage training framework for NMT where we
fine-tune a base NMT model on subsets of data, selected by both deterministic
scoring using pre-trained methods and online scoring that considers prediction
scores of the emerging NMT model.
Through comprehensive experiments on six language pairs comprising low- and
high-resource languages, we have shown that our curriculum strategies
consistently demonstrate better quality and faster convergence.
Publication: EMNLP-2022
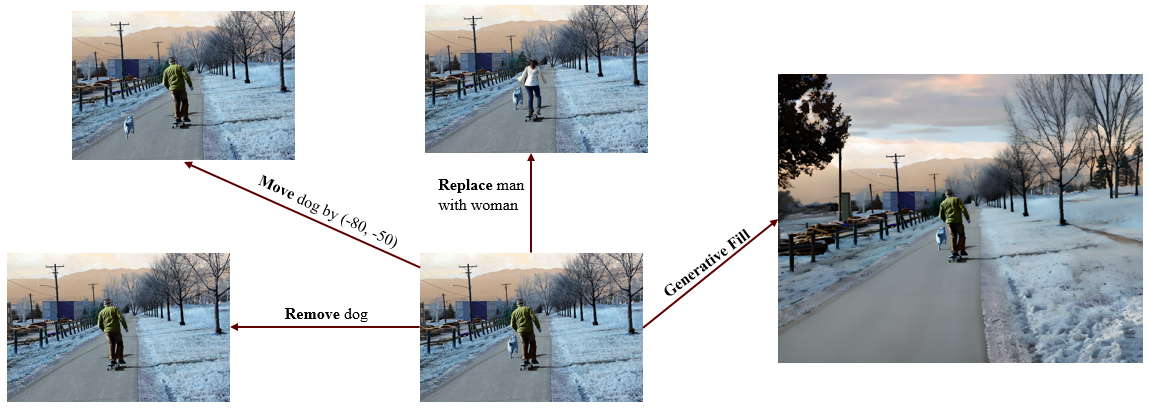
Image Editing in the WILD
The ability to edit images in a realistic and visually appealing manner is a
fundamental requirement in various computer vision applications. In this paper,
we present ImEW, a unified framework designed for solving image editing
tasks.
ImEW utilizes off-the-shelf foundation models to address four essential
editing tasks: object removal, object translation, object replacement, and
generative fill beyond the image frame. These tasks are accomplished by
leveraging the capabilities of state-of-the-art foundation models, namely the
Segment Anything Model, Grounding DINO, LaMa, and Stable Diffusion. These models
have undergone extensive training on large-scale datasets and have exhibited
exceptional performance in understanding image context, object manipulation, and
texture synthesis.
Through extensive experimentation, we demonstrate the effectiveness and
versatility of ImEW in accomplishing image editing tasks across a wide
range of real-world scenarios. The proposed framework opens up new possibilities
for realistic and visually appealing image editing and enables diverse
applications requiring sophisticated image modifications. Additionally, we
discuss the limitations and outline potential directions for future research in
the field of image editing using off-the-shelf foundation models, enabling
continued advancements in this domain.
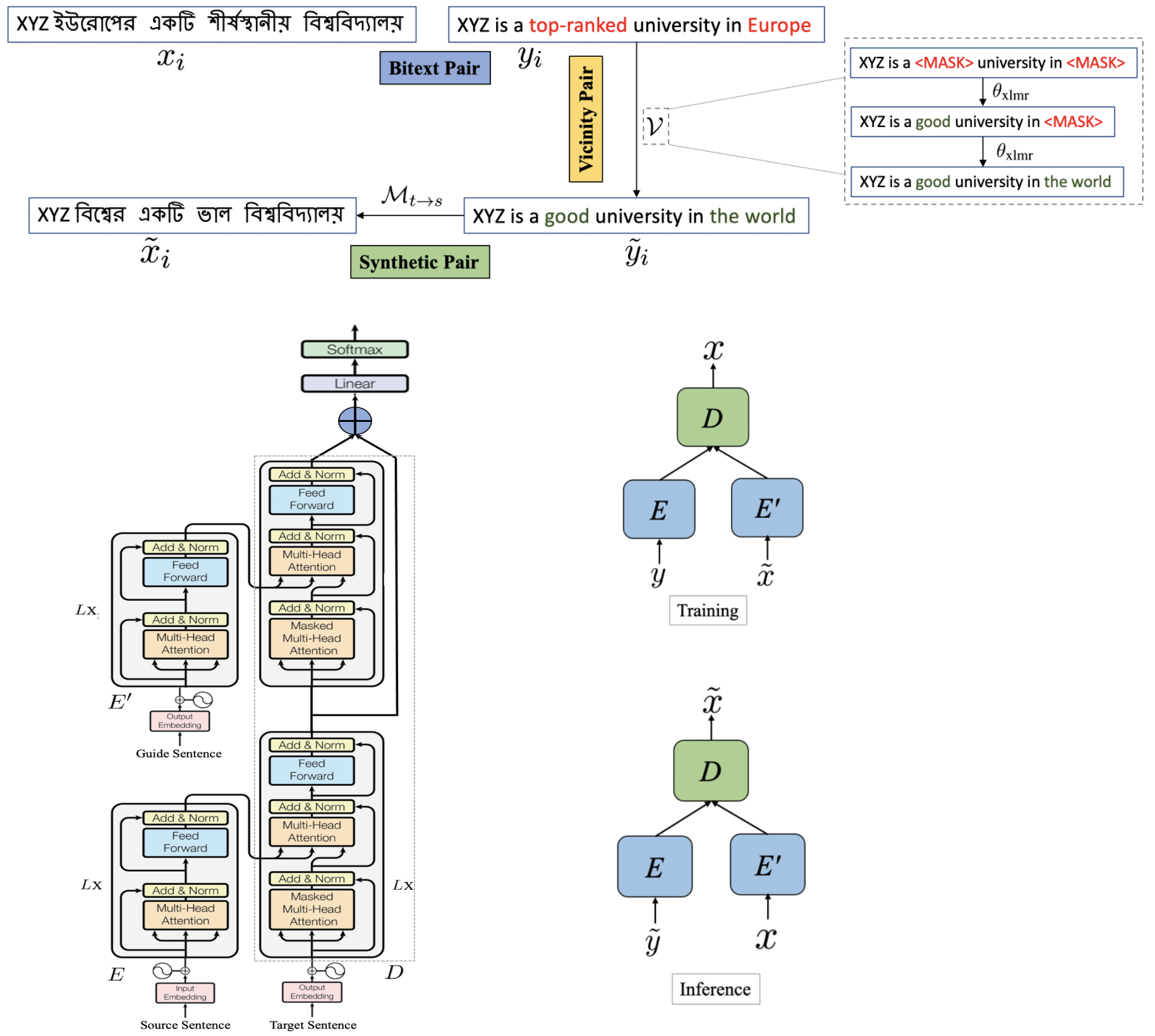
Exploiting BiText Vicinity for Low-Resource NMT
The success of Neural Machine Translation (NMT) largely depends on the
availability of large bitext training corpora. Due to the lack of such large
corpora in low-resource language pairs, NMT systems often exhibit poor
performance. Extra relevant monolingual data often helps, but acquiring it could
be quite expensive, especially for low-resource languages. Moreover, domain
mismatch between bitext (train/test) and monolingual data might degrade the
performance. To alleviate such issues, we propose AugVic, a novel data
augmentation framework for low-resource NMT which exploits the vicinal samples
of the given bitext without using any extra monolingual data explicitly.
It can diversify the in-domain bitext data with finer-level control. Through
extensive experiments on four low-resource language pairs comprising data from
different domains, we have shown that our method is comparable to the
traditional back-translation that uses extra in-domain monolingual data. When we
combine the synthetic parallel data generated from AugVic with the ones
from the extra monolingual data, we achieve further improvements. We show that
AugVic helps to attenuate the discrepancies between relevant and
distant-domain monolingual data in traditional back-translation.
Publication: ACL-2021
Data Augmentation for Cross-Lingual NLP
Transfer learning has yielded state-of-the-art (SoTA) results in many supervised
natural language processing tasks. However, annotated data for every target task
in every target language is rare, especially for low-resource languages. We
target to solve cross-lingual adaptation problems from a source language
distribution to an unknown target language distribution, assuming no training
labels are available for the target language task.
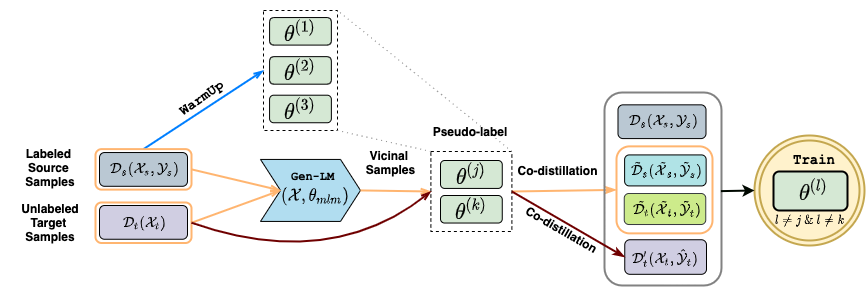
In this project, we propose UXLA, a generic data augmentation
framework for
self-supervised learning in zero-resource transfer learning scenarios. At its
core, UXLA performs simultaneous self-training with data augmentation and
unsupervised sample selection. We augment data from the unlabeled
training examples in the target language as well as from the virtual input
samples (eg sentences) generated from the vicinity distribution of the source
and target language sentences. With the augmented data, UXLA performs
simultaneous self-learning with an effective distillation strategy to learn a
strongly adapted cross-lingual model from noisy (pseudo) labels for the target
language task. We propose novel ways to generate virtual input samples using
XLMR - a multilingual masked language model, and get reliable task labels by
simultaneous multilingual co-training.
To show our proposed methods' effectiveness, we conduct
extensive experiments on zero-resource cross-lingual transfer tasks for Named
Entity Recognition (XNER) and Natural Language Inference (XNLI).
UXLA achieves SoTA results in both tasks, outperforming the baselines by a
good margin. With an in-depth model dissection, we demonstrate the cumulative
contributions of different components to UXLA's success.
Publication: ACL-2021
Bilingual Lexicon Induction with Limited Supervision
Most of the successful and predominant methods for Bilingual Lexicon Induction
(BLI) are mapping-based, where a linear mapping function is learned with the
assumption that the word embedding spaces of different languages exhibit similar
geometric structures i.e. approximately isomorphic}). However, several
recent studies have criticized this simplified assumption showing that it does
not hold in general even for closely related languages. In this work, we propose
a novel semi-supervised method to learn cross-lingual word embeddings for
BLI. Our model is independent of the isomorphic assumption and uses
non-linear mapping in the latent space of two independently pre-trained}
autoencoders. Through extensive experiments on fifteen (15) different language
pairs (in both directions) comprising resource-rich and low-resource languages
from two different datasets, we demonstrate that our method outperforms existing
models by a good margin. Ablation studies show the importance of different model
components and the necessity of non-linear mapping.
Publication: EMNLP-2020

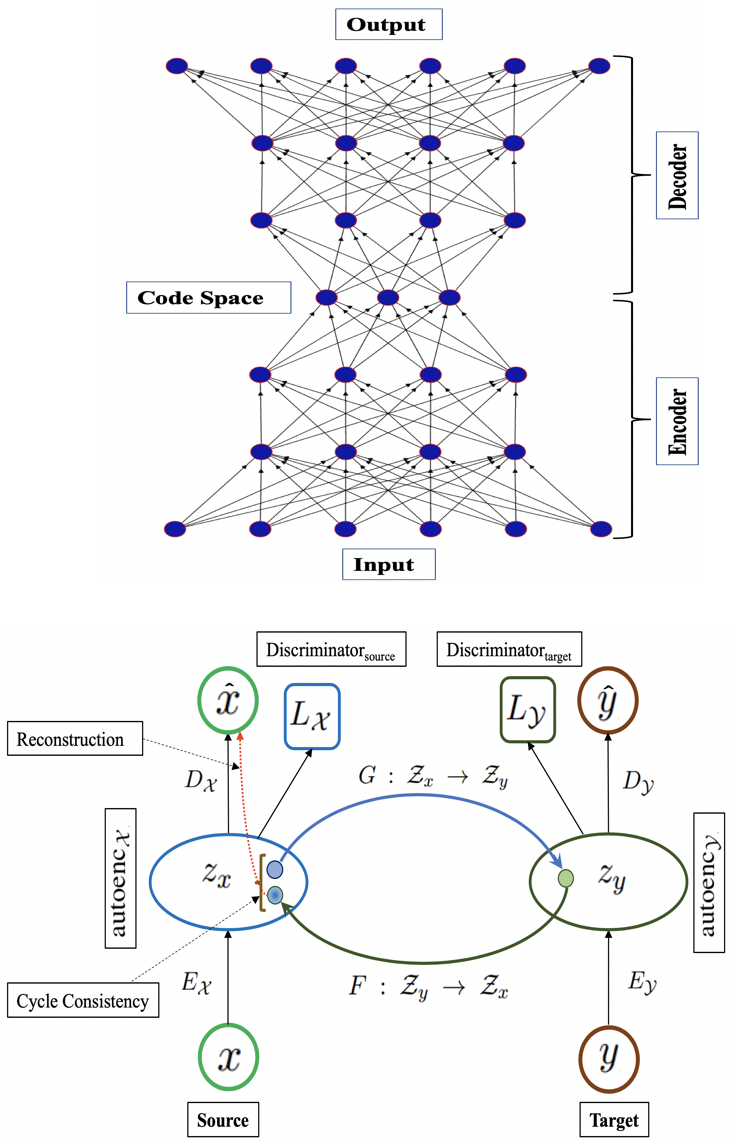
Unsupervised word translation
Suppose we are given
monolingual word embeddings for source and target languages. We do not
have any
initial dictionary or external cross-lingual signal. Our
goal is to learn word translation (a.k.a. bilingual lexicon induction)
i.e. for
a given source word, we want its translation in the target domain.
Cross-lingual word embeddings learned from monolingual embeddings have a
crucial
role in many downstream tasks, ranging from machine translation to transfer
learning.
Adversarial training has shown impressive success in learning
cross-lingual embeddings
and the associated word translation task without any parallel data by mapping
monolingual
embeddings to a shared space. In this project, we investigate
adversarial autoencoder for unsupervised word translation and propose
two novel extensions to it that yield more stable training and improved
results.
Our method includes
regularization terms to enforce
cycle consistency and
input reconstruction, and puts the target encoders as an adversary
against the
corresponding discriminator.
We use two types of
refinement procedures sequentially after obtaining the trained encoders
and mappings
from the adversarial training, namely,
refinement with Procrustes solution and
refinement with symmetric re-weighting.
Extensive experimentations with European, non-European and low-resource
languages
show that our method achieves better performance than existing adversarial and
non-adversarial
approaches and is also competitive with the supervised system. Along with
performing
comprehensive ablation studies to understand the contribution of different
components
of our adversarial model, we also conduct a thorough analysis of the refinement
procedures
to understand their effects.
Publication: NAACL-HLT 2019 , CL Journal 2020
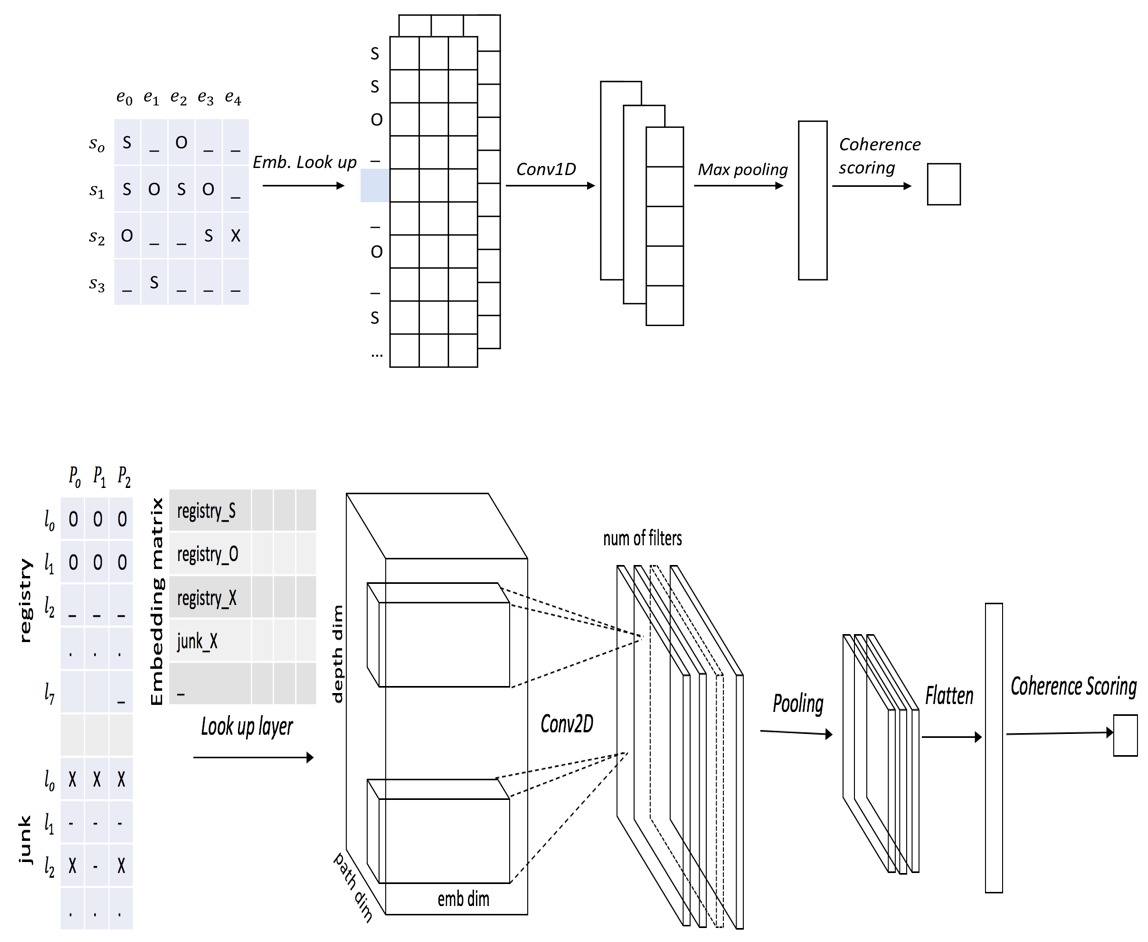
Neural Coherence Model
Sentences in a text or a conversation do not occur independently; rather they
are connected to form a coherent discourse
that is easy to comprehend.
Coherence models are computational models that can distinguish a coherent
discourse
from incoherent ones. It has ranges of applications in text generation,
summarization,
and coherence scoring.
In this project, we conduct our research in
two steps.
First, we propose improvements to the recently proposed
neural entity grid model by
lexicalizing its entity transitions. We propose methods based on word
embeddings
to achieve better generalization with the lexicalized model.
Second, we extend the model to asynchronous conversations by
incorporating the
underlying conversational structure in the entity grid representation and
feature
computation. For this, we propose a novel grid representation for asynchronous
conversations
and adapt the convolution layer of the neural model accordingly.
Our model achieves state of the art results on standard coherence
assessment tasks
in monologue and conversations outperforming existing models. We also
demonstrate
its effectiveness in reconstructing thread structures.
Publication: ACL 2018
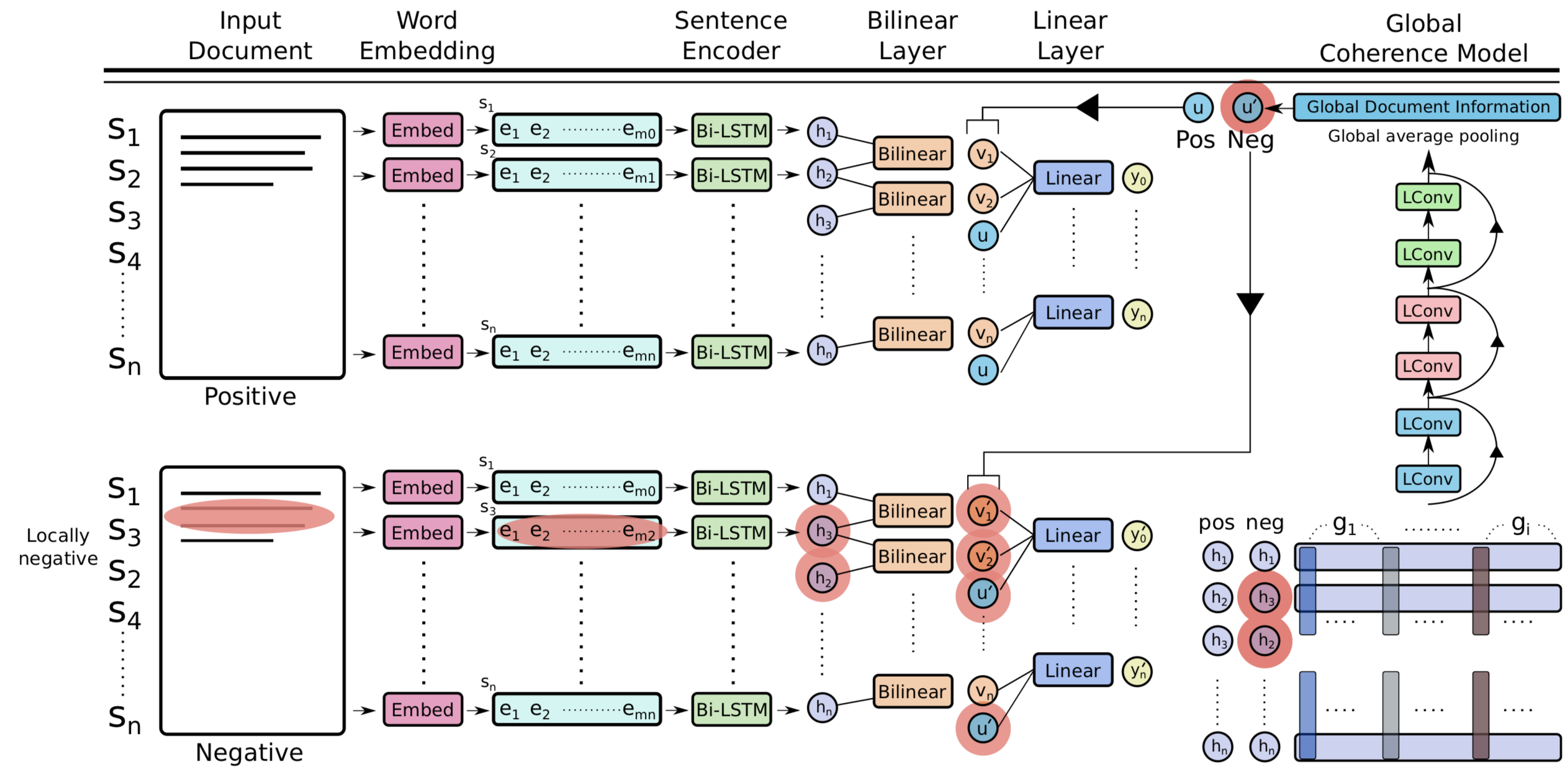
Unified Coherence Model
In this project, we work on the limitations of existing models which
underperform on tasks that require the model to be sensitive
to local contexts such as candidate ranking in conversational dialogue and in
machine
translation.
We propose a
unified coherence model that incorporates
sentence grammar,
inter-sentence coherence relations, and
global coherence patterns in a single framework. We use an
LSTM sentence encoder with explicit language model loss to capture the
syntax.
Inter-sentence discourse relations are modeled with a
bilinear layer, and a
lightweight convolution-pooling is used to capture the attention and
topic structures
(global coherence patterns ).
We evaluate our models on both local and global discrimination tasks on the
benchmark
dataset. Our results show that our approach outperforms existing methods by a
wide
margin in both tasks.
Publication: EMNLP-IJCNLP 2019
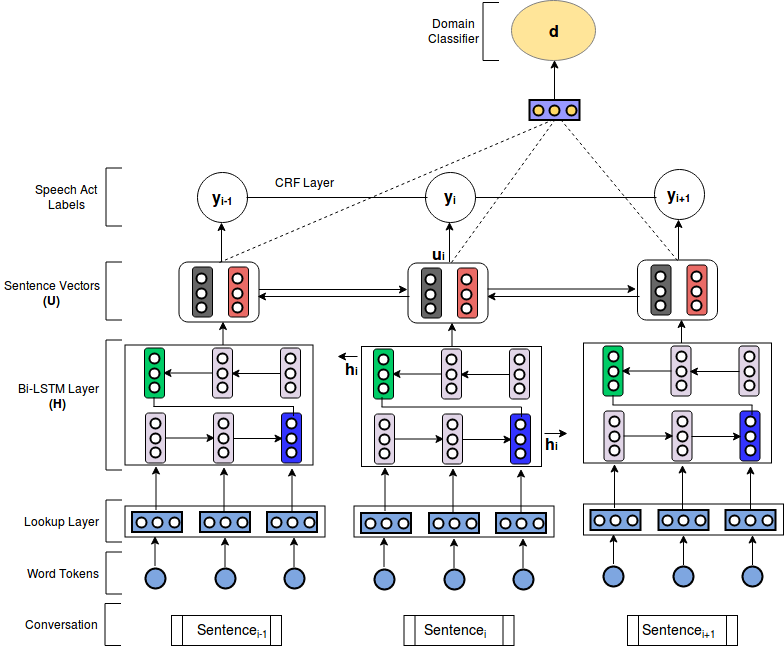
Speech Act Recognition in Asynchronous Conversation
With the advent of Internet technologies, communication media like emails and
discussion forums have become common-place
for discussing work, issues, events, and experiences. Participants in these
media
interact with each other
asynchronously by writing at different times. Participants in an
asynchronous
conversation interact with each other in complex ways, performing certain
communicative
acts like asking questions, requesting information or suggesting something.
These
are called
speech acts.
Unlike synchronous conversations (e.g. meeting, phone), modeling
conversational
dependencies between sentences in an asynchronous conversation are challenging.
The
conversational flow often lacks sequential dependencies in its
temporal/chronological
order.
For example, if we arrange the sentences as they arrive in the
conversation,
it becomes hard to capture any dependency between the acts types because the two
components of the adjacency pairs can be far apart in the sequence. This leaves
us
with
one open research question:
how do we model the dependencies between sentences in a single comment and
between
sentences across different comments? Another major problem is
insufficient training data in the asynchronous domains.
In this project, we propose methods to effectively leverage abundant
unlabeled conversational
data and the available labeled data from synchronous domains. We carry out our
research
in
three main steps.
First, we introduce an end-to-end neural architecture based on a
hierarchical
LSTM encoder with a Softmax or conditional random fields (CRF) output layer, and
show that our method outperforms existing methods when trained on in-domain data
only.
Second, we improve our initial SAR models by semi-supervised learning in
the
form of pretrained word embeddings learned from a large unlabeled conversational
corpus.
Finally, we adapt our hierarchical LSTM encoder using domain adversarial
training
to leverage the labeled data from synchronous domains by explicitly modeling the
shift in the two domains.
We evaluate our models on three different asynchronous datasets containing
forum
and email conversations, and on the MRDA meeting corpus. Our main findings are:
- hierarchical LSTMs outperform existing methods when trained on in-domain data for both synchronous and asynchronous domains, setting a new state-of-the-art
- conversational word embeddings yield significant improvements over off-the-shelf ones
- domain adversarial training improves the results by inducing domain-invariant features.
Publications: CL Journal 2018, NAACL-HLT 2019